DTACT Fusion goes beyond technological boundaries and allows the creation of an information landscape in which data remains in its original source.
Combine this with a virtual mesh of all connected systems, infrastructures or sources is created for instant insight discovery and action purposes.
Mix data like a mad scientist and create a robust common operational picture
DTACT developed a unique and fully agnostic technology to break the data silos, to speed up any Data Warehouse project, or even to render them completely unnecessary.
By following a traditional Extract, Transform, and Load (ETL) process or by creating a Data Mesh, we allow you to tap into any data source, in any language or any format using our RAW data and NONTOLOGY™ methodology.
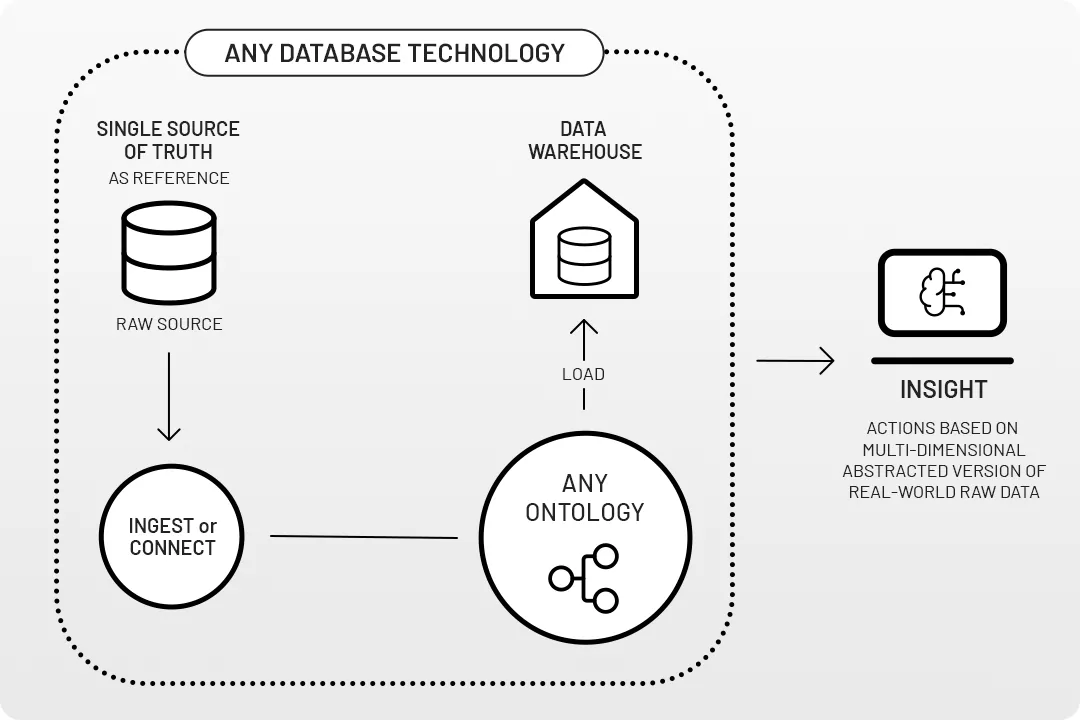
The RAW data principle
Owning many different types of data sources require more flexibility when it comes to fusing data. Ideally, you want to access data 'as- is' and not worry about reformatting it. With our technology, you'll always have the opportunity to go back to the source with the following benefits:
- Keeping your data source in its original raw format
- Defining and labelling granular access and retention controls from the start
- Extensive knowledge management options supporting decision-making between RAW data formats, queries, AI, or insights produced by humans
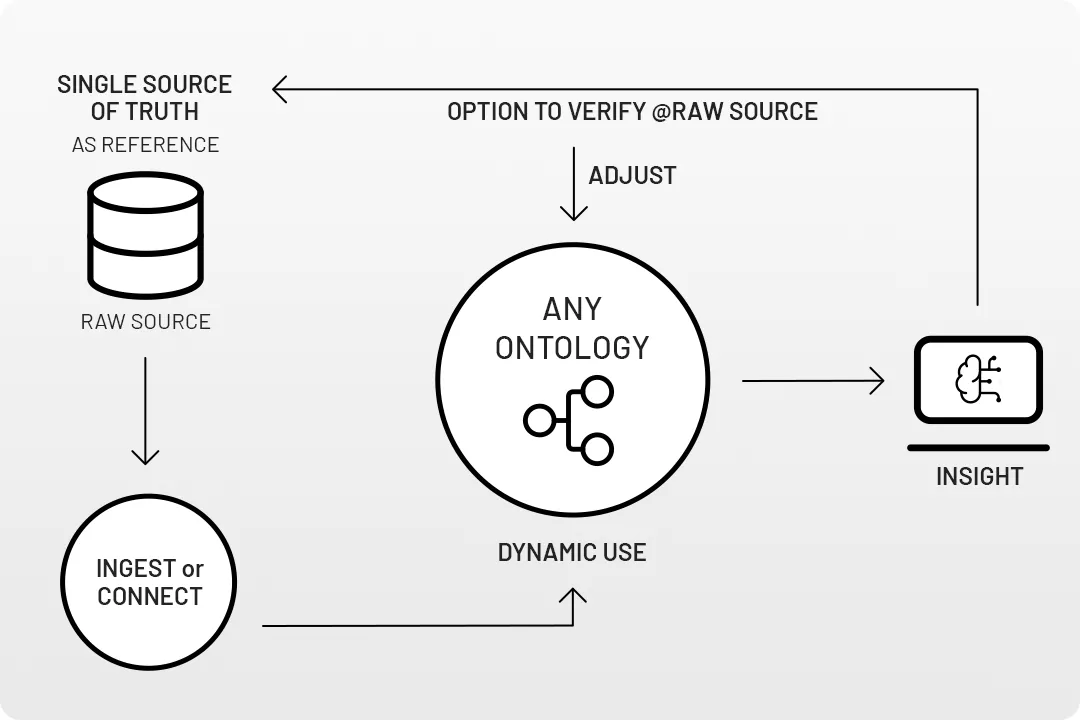
The NONTOLOGY™ principle
We're not saying having an ontology isn't useful at certain points in time but what if it would be completely unnecessary to define this upfront? Wouldn't that save up a lot of time and frustration?
By using DTACT's NONTOLOGY™ principle, it is no longer necessary for partners, internal departments or distributed teams to agree on the standardization of data models first before having meaningful data integration. Book a demo with us to see how this works together with our RAW data principle.

Fusion Mesh:
A data search engine
With Raven Fusion Mesh, you can search through
connected, structured, unstructured, and siloed
data sources to find answers based on the query
command. And, like well-known search engines,
you'll have immediate results without building a
data lake or datawarehouse first.
Think of your organization's data like a big city with
different neighborhoods. Each neighborhood represents
a different aspect of the data. In a data mesh, instead
of trying to cram everything into one central downtown
area, you decentralize. Each neighborhood manages
its own data, making it easier to navigate and control.